To visualise it more simply, let’s assume we have to find a word in the dictionary (you would use indexes to speed it up, but it would still be a time-consuming task). Or, you have to find a name in the encyclopaedia (lettered from A-C). It would be fair to assume data would be found easily here. This is an example of partitioning, breaking big chunks of data so that small chunk is processed easily.
Partitioning With Replication
Wait a second? Why are these two terms together? Since we’re breaking data into small chunks, why are we replicating it? Let’s take a step back and take a closer look. Replication is done to prevent data loss. We can store our partitions on different nodes and store the replicas for fault tolerance. To partition we can use a key-value pair, the value being our data and the key being a unique entity associated with data. Now we can store these key-value pairs in different ways so that our processing is fast. Our main task is to find a way these values can be found quickly based on the key. The key mentioned above is a primary key (unique entity meaning no two pieces of data can have the same key).
Primary Indexing
Primary indexing is defined mainly on the primary key of the data file, in which the data file is already ordered based on the primary key. To explain it simply, we’ve sorted unique keys in some order and we find the value. How hard can it be? As it turns out, very.
Partitioning by Key Range
Let’s make an encyclopaedia-like structure and store data in it—data for A-B in one partition, C-D in another and so on. But we can see a problem here: uneven distribution. We’ve 20 names starting with A, and two with B. What will happen to our aim of speeding up the query of partition A?
Partitioning by Hash of Key
By hashing our key, it will generate a random number. The result of the hash is evenly distributed between 0 and 2³²− 1(32-bit hash function). Each partition can be assigned a range of hash. But there are still issues. The close keys are now away from each other.
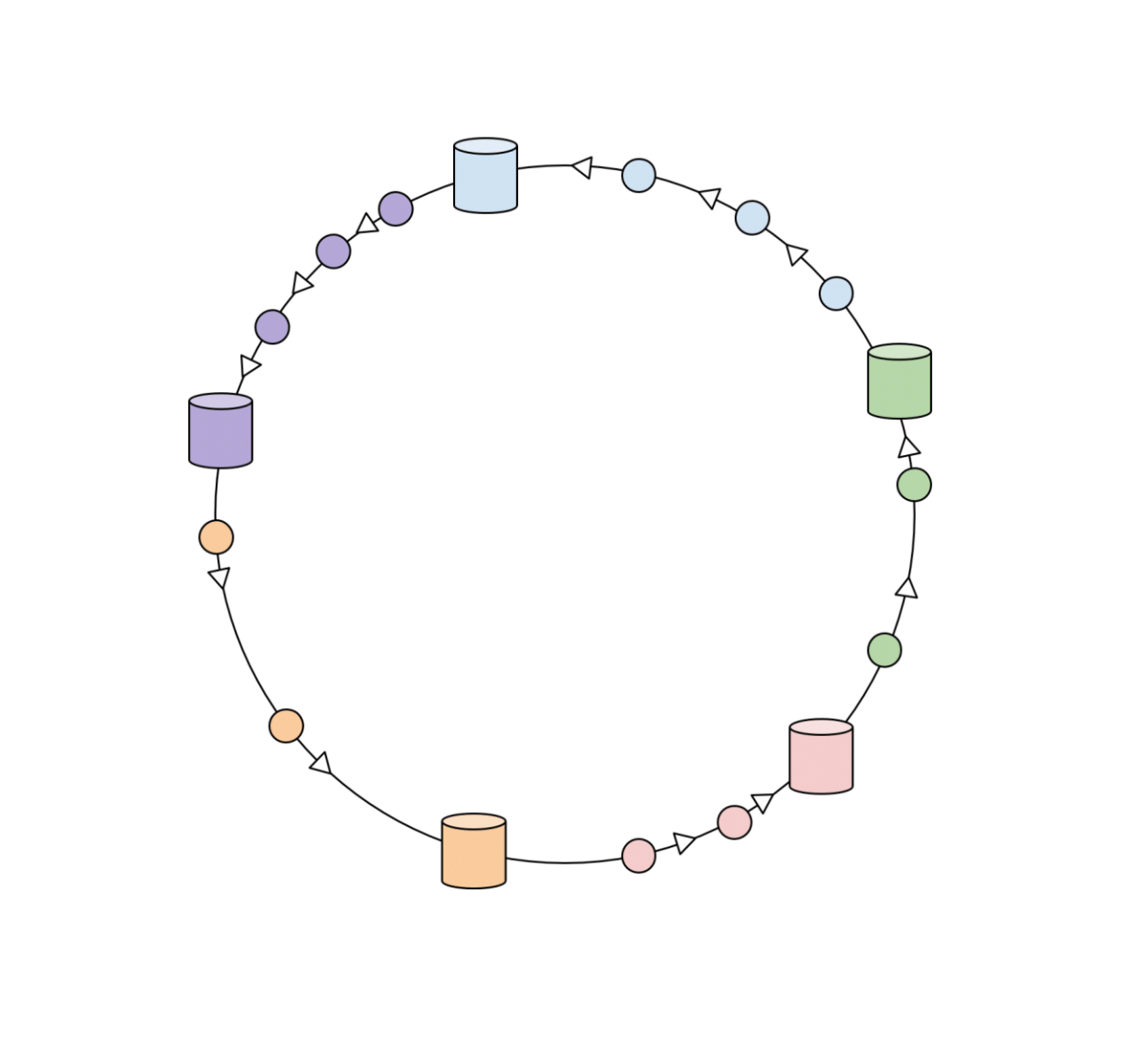
Consistent Hashing
As the name suggests, we’re trying to make hashing consistent. But how can we do that? We assign them a position on an abstract circle so that no matter how many servers are added or removed, our hashes aren’t disturbed. We distribute each object key so that they belong in the server whose key is closest, in a counterclockwise direction (or clockwise, depending on the conventions used). In other words, to find out which server to ask for a given key, we need to locate the key on the circle and move in the ascending angle direction until we find a server.
Secondary Indexes
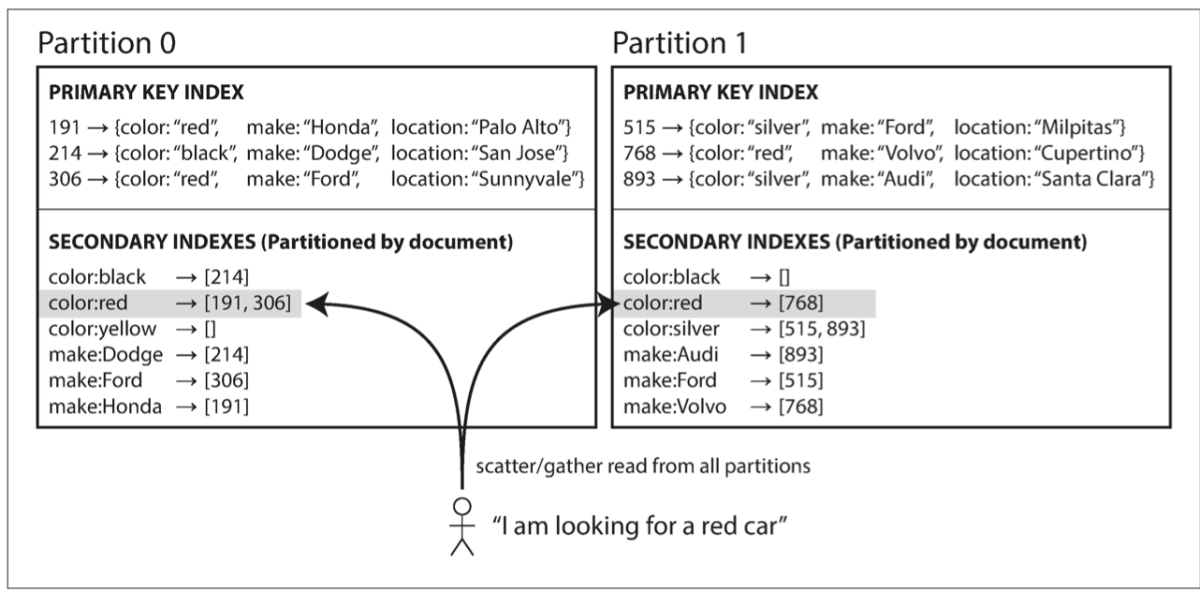
Finding info based on a primacy index is possible but we can optimise, right? We use secondary indexes for this purpose, meaning it’s not used to find the record uniquely (like the primary key) but to help us search occurrences of a particular value. Let’s suppose we have to find every user in a database who subscribed to me on Medium, how do we do that? The primary index would help me find the partition (a block of data made by breaking the original database into pieces), but how do I find all occurrences of your name in my follower list? Thus, we do secondary indexing to look for appearances. Secondary indexing is achieved in two ways : document-based secondary indexing on a partition or term-based secondary indexing on a partition.
Document-based Secondary Indexing
This is a sort of local indexing in which we store all the appearances of data in a partition, meaning we would be storing appearances of “A” in partition ‘1’. Let’s assume it to be 3 and 4 appearances in partition 2’. So if asked about the total appearances of “A”, we would have to add all appearances i.e, 3+4 (7). This is not a suggested method as we will be looking into all the partitioning.
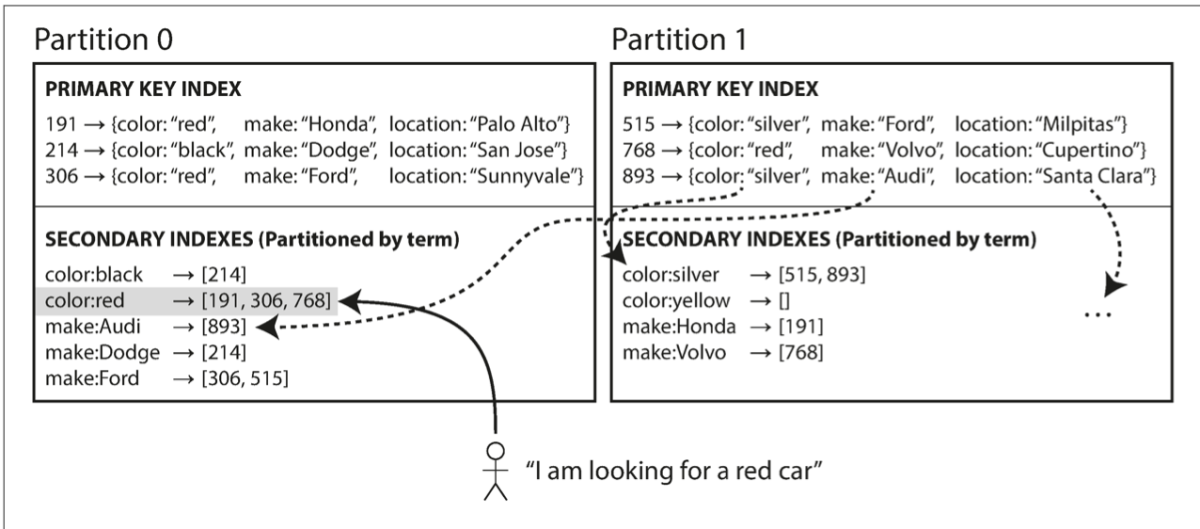
Term-based Secondary Indexing
In this indexing, we map the appearances of a term in all partitions to one location, known as the Global Index. We’re not storing all secondary indexes at the same location as our goal of partitioning would be defeated; thus we store them on different partitions as well. The search here is much faster as we aren’t looking in all partitions for a secondary index. It’s sort of like we’re doing primary indexing again.
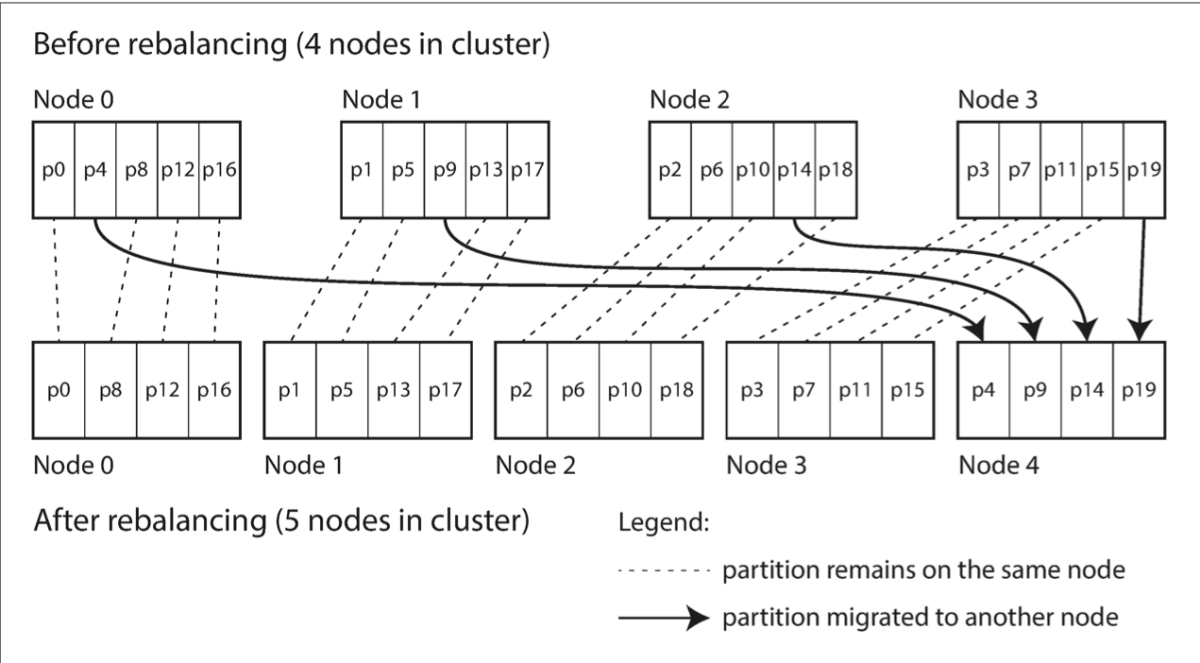
Rebalancing Partitions
Partitioning is balancing data in pieces so that processing becomes simple. But we’re getting more and more data while we’re doing this right? So when we want to rebalance our partitions, we have to make sure our database is open to read/write. If we add a few nodes to the system, it would steal some partitions from other nodes until things are balanced (so that data is consistently read). Similarly, if a node is removed, extra partition is sent to all. Elasticsearch and Couchbase use this method of rebalancing as well. We can do the above processing dynamically by breaking the partition into two parts if it’s too big (like this blog) or merging them if it’s too small. This method is helpful as it adapts to total data volume.
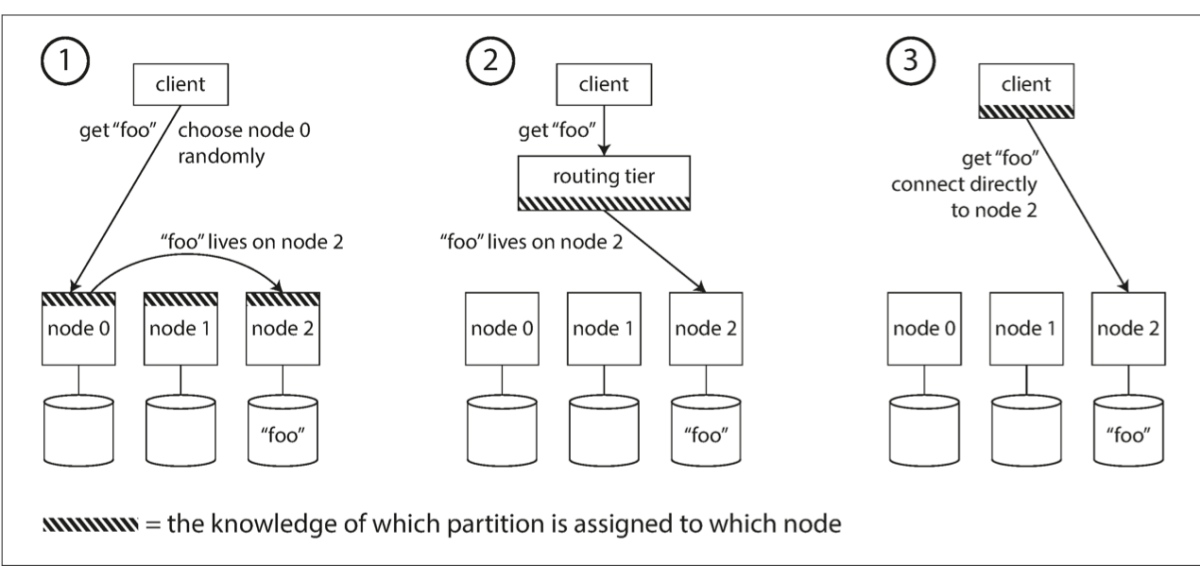
Request Routing
One thing that is simple and clear is that when a user requests a server we can decide which partition to pick data from. So we try to channel our requests to the partition that contains the data so that the least amount of time is taken. There are different ways to send requests from the client to the server:
It is unaware of which partition data is present. So it sends to random node and from there re-sent to correct node. The client knows exactly where data is stored (in which node). The client sends to a load balancer, which knows where data can be found.
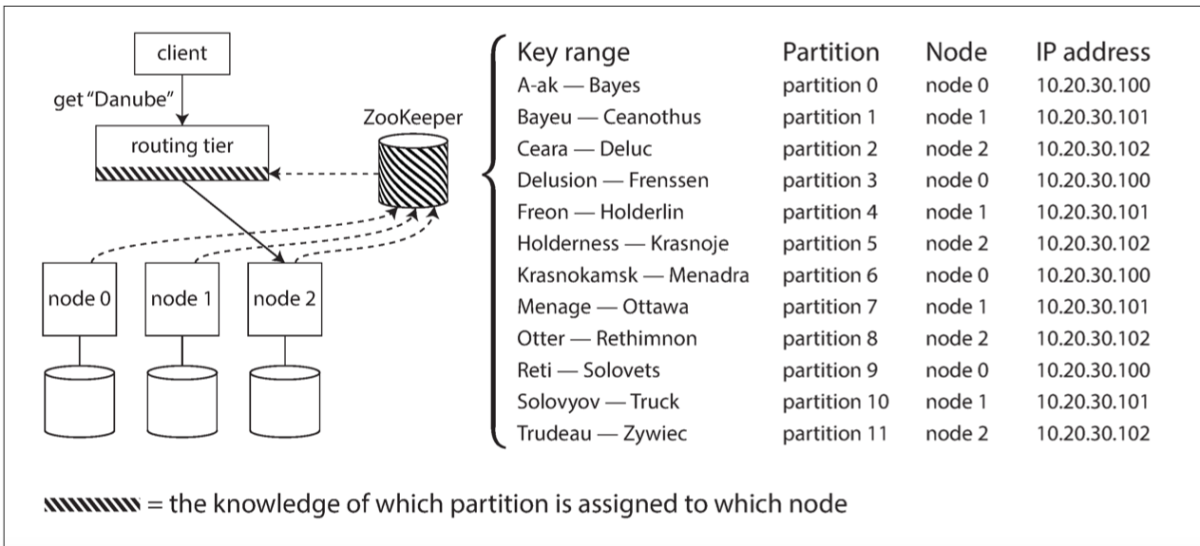
But what if we maintain a log book that knows which node has which partitioning so when a request is received, we find which partition is needed and which node it belongs to? Zookeeper is a popular coordination service (also used in Kafka) which can help us with this tracking. I guess this was a lot of information, so let’s take a break until the next blog! This article is accurate and true to the best of the author’s knowledge. Content is for informational or entertainment purposes only and does not substitute for personal counsel or professional advice in business, financial, legal, or technical matters. © 2022 Shivam Sourav Jha